Secure & Performant Bittensor Validation
By Wesley Graham, Infrastructure Engineer
At Unit 410, we prioritize security and performance for the dozens of networks we support (Bittensor included). Our team operates using advanced infrastructure, secure practices, and custom-built tools.
Running on Dedicated, Performant Hardware
Performance starts at the foundation, which is why we operate dedicated hosts per subnet. These hosts are appropriately provisioned - with some subnets operating on “common” instance types such as Intel Cascade Lake processors with 32 GB RAM, Virtual Proxies, and SSD/NVMe-based storage options. If GPUs are required, then they are provisioned with some of the most performant cloud-available GPUs on the market or these.
GPU based subnets are provisioned using various automated tools including NVIDIA install kits, ansible roles, and drivers.
Hardware selections are made based on the compute requirements documented by subnet owners, and monitoring metrics are tuned regularly.
Unit 410 automatically builds subnet code from source on changes, runs dedicated infrastructure, and does not copy weights on the subnets it operates.
Security at the Forefront
Security is at the core of our operations. We take several measures to run nodes as securely as possible, including:
- Port Lockdown: Unneeded ports are locked down to prevent unauthorized access.
Axonsare not published when possible. - Wandb Logging:
Wandbis disabled by default to prevent secret leaks from logs or other metadata. - Dedicated Connections: Subnet validators are connected to a set of internal subtensor nodes.
Containerization
Subnet containerization is central to our approach.
An example Dockerfile:
# syntax=docker/dockerfile:1
FROM pytorch/pytorch:1.13.1-cuda11.6-cudnn8-devel
# Loosely based on the Dockerfile here: https://github.com/opentensor/bittensor/blob/master/Dockerfile
ARG DEBIAN_FRONTEND=noninteractive
ARG VERSION
ENV VERSION=${VERSION}
# NVIDIA key migration
RUN apt-key del 7fa2af80
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/3bf863cc.pub
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu2004/x86_64/7fa2af80.pub
# Update the base image
RUN apt update && apt upgrade -y
# Install dependencies
RUN apt install -y curl sudo nano git htop netcat wget unzip python3-dev python3-pip tmux apt-utils cmake build-essential
# Upgrade pip
RUN pip3 install --upgrade pip
# Download source repository and prepare to install
RUN mkdir -p /root/.bittensor/
RUN git clone --recursive https://github.com/opentensor/bittensor.git
RUN mv ./bittensor/ /root/.bittensor/
WORKDIR /root/.bittensor/bittensor
RUN git checkout ${VERSION}
# Install via python/pip
RUN python3 -m pip install -e .
# Install cubit (requirement for mining/registering/etc with GPU)
RUN pip3 install https://github.com/opentensor/cubit/releases/download/v1.1.2/cubit-1.1.2-cp310-cp310-linux_x86_64.whl
# Increase ulimit to 1,000,000
RUN prlimit --pid=$PPID --nofile=1000000
LABEL org.opencontainers.image.authors="unit410"
LABEL org.opencontainers.image.title="Containerized GPU-Enabled Bittensor"
LABEL org.opencontainers.image.documentation="https://www.github.com/opentensor/bittensor"
ENTRYPOINT ["btcli"]
btcli containerization
FROM us-docker.pkg.dev/pc-deps/us.gcr.io/bittensor-cli:v6.12.1
ARG VERSION
ENV VERSION=${VERSION}
RUN apt install -y gcc libnfnetlink-dev libnetfilter-queue-dev
WORKDIR /root/.bittensor
RUN git clone --recursive https://github.com/eclipsevortex/SubVortex
WORKDIR /root/.bittensor/SubVortex
RUN git checkout ${VERSION}
# Install
RUN python3 -m pip install -r requirements.txt
RUN python3 -m pip install -e .
# Increase ulimit to 1,000,000
RUN prlimit --pid=$PPID --nofile=1000000
LABEL org.opencontainers.image.authors="unit410"
LABEL org.opencontainers.image.title="Containerized GPU-Enabled Bittensor Subnet 7 Validator"
LABEL org.opencontainers.image.documentation="https://github.com/eclipsevortex/SubVortex"
LABEL org.opencontainers.image.version=${VERSION}
ENTRYPOINT ["python3"]
subnet containerization
- Consistency Across Environments: By Docker-izing all subnets, we ensure that our environment is consistent across hosts and locations.
- Rapid Migration: Containerization allows us to quickly migrate to new host types or locations without disrupting service (or between Cloud Providers / Data Centers).
- Version Control: We are able to pin specific, secure versions of the
bittensor-clito be used on each subnet independent of their specified version(s). - Rapid Rollbacks: If issues arise, we can swiftly revert to a previously healthy image, minimizing downtime and maintaining service integrity.
- State Mounts: On stateful subnets, it is important to persist said state across validator upgrades and restarts. We utilize volume mounts to ensure that upgrades do not reset accumulated validator state.
Custom Tools for Stability and Uptime
Unit 410 has built its own internal tooling to ensure maximum stability and uptime.
Auto-Upgrader

Unit 410’s “auto-upgrader” systemd service runs alongside each subnet, polling subnet repositories for new commits and releases via an auto-upgrade script specific to our build environment.
Example script for GCP-stored images:
#!/bin/bash
SERVICE_NAME="<validator service name here>"
IMAGE_REPO="<image repo here>"
UPGRADE_THRESHOLD_MINUTES=15
function get_latest_image_digest() {
local latest_digest=$(gcloud container images list-tags ${IMAGE_REPO} --limit=1 --format='get(digest)' | head -n 1)
echo "${IMAGE_REPO}@${latest_digest}"
}
function get_current_image_digest() {
# removed
}
function get_image_age_minutes() {
local latest_image_info=$(gcloud container images list-tags ${IMAGE_REPO} --limit=1 --format="get(timestamp)")
local latest_image_timestamp=$(echo $latest_image_info | sed 's/datetime=\([0-9-]* [0-9:]*\).*/\1/')
local latest_image_epoch=$(date -d "$latest_image_timestamp" +%s)
local current_epoch=$(date +%s)
echo $(( ($current_epoch - $latest_image_epoch) / 60 ))
}
function update_service() {
echo "INFO: A new image that is older than ${UPGRADE_THRESHOLD_MINUTES} minutes is available. Pulling the latest image... (this will take some time)"
gcloud auth configure-docker
# Pull the latest image
docker pull ${IMAGE_REPO} > /dev/null
# Restart the service with the new image
echo "Restarting the ${SERVICE_NAME} service..."
systemctl restart ${SERVICE_NAME}.service
}
LATEST_IMAGE_DIGEST=$(get_latest_image_digest)
echo "Latest Image Digest: ${LATEST_IMAGE_DIGEST}"
CURRENT_IMAGE_DIGEST=$(get_current_image_digest)
echo "Current Image Digest: ${CURRENT_IMAGE_DIGEST}"
IMAGE_AGE_MINUTES=$(get_image_age_minutes)
echo "Image age in minutes: ${IMAGE_AGE_MINUTES}"
# Check if there is a new image that is older than UPGRADE_THRESHOLD_MINUTES minutes
if [ "$LATEST_IMAGE_DIGEST" != "$CURRENT_IMAGE_DIGEST" ] && [ ${IMAGE_AGE_MINUTES} -gt $UPGRADE_THRESHOLD_MINUTES ]; then
update_service
else
echo "SUCCESS: No new images that are older than ${UPGRADE_THRESHOLD_MINUTES} minutes old. No action taken."
fi
This solution, independent of the pm2 services that some subnets offer, ensures that we upgrade to the latest subnet image within 15-30 minutes of a new build. This tool is generalized across subnets - subnet owners do not need to offer automated upgrades via pm2 or any other mechanism for us to operate this feature.
When appropriate, we also disable this feature for manual review of code, changes, and deployment.
Service Restarter

Service restarter monitors subnet validator processes for stalls or other issues. If problems are detected, the service restart script automatically restarts the validator process, helping ensure continuous operation.
Example script:
#! /usr/bin/env bash
set -eou pipefail
function restart_service() {
echo "Weights have not been updated, stopping the core-validator"
# Ensure the docker container doesnt restart once we have killed it
systemctl stop <your validator service name>
echo "Service has been stopped, restarting the service"
systemctl start <your validator service name>
echo "The service is restarted."
}
function get_validator_service_runtime() {
local service_name="<your validator service name>"
# Get the time when the service was last started
local service_start_time=$(systemctl show -p ActiveEnterTimestamp "$service_name" | cut -d'=' -f2)
# Convert it to seconds since epoch
local service_start_time_sec=$(date --date="$service_start_time" +%s)
# Current time in seconds since epoch
local current_time_sec=$(date +%s)
# Calculate the difference in hours and echo it
echo $(( (current_time_sec - service_start_time_sec) / 3600 ))
}
# Check if netuid is passed as an argument
if [ $# -lt 3 ]; then
echo "Usage: $0 <netuid> <restart_threshold_hours> <weights_last_set_threshold>"
exit 1
fi
netuid=$1
restart_threshold_hours=$2
weights_last_set_threshold=$3
echo "Checking the last time the service updated weights to see if it needs to be restarted"
python3 /opt/bittensor/weight-check.py $netuid $weights_last_set_threshold
if [ $? -eq 0 ]; then
echo "Weights have been updated, <your validator service name> should be healthy"
elif [ $(get_validator_service_runtime) -lt $restart_threshold_hours ]; then
echo "The service has been running for less than ${restart_threshold_hours} hours, no action taken"
else
restart_service
exit 0
fi
Validator Processes are restarted based on two thresholds:
restart_threshold_hours: the number of hours since a validator has last set weightsweights_last_set_threshold: the number of blocks since a validator has set weights
Monitoring & Dashboards
We have previously documented and open-sourced a series of useful metrics for bittensor operators:
Key Performance Metrics We Monitor
We have multiple metrics that we monitor, starting with vTrust across all subnets:
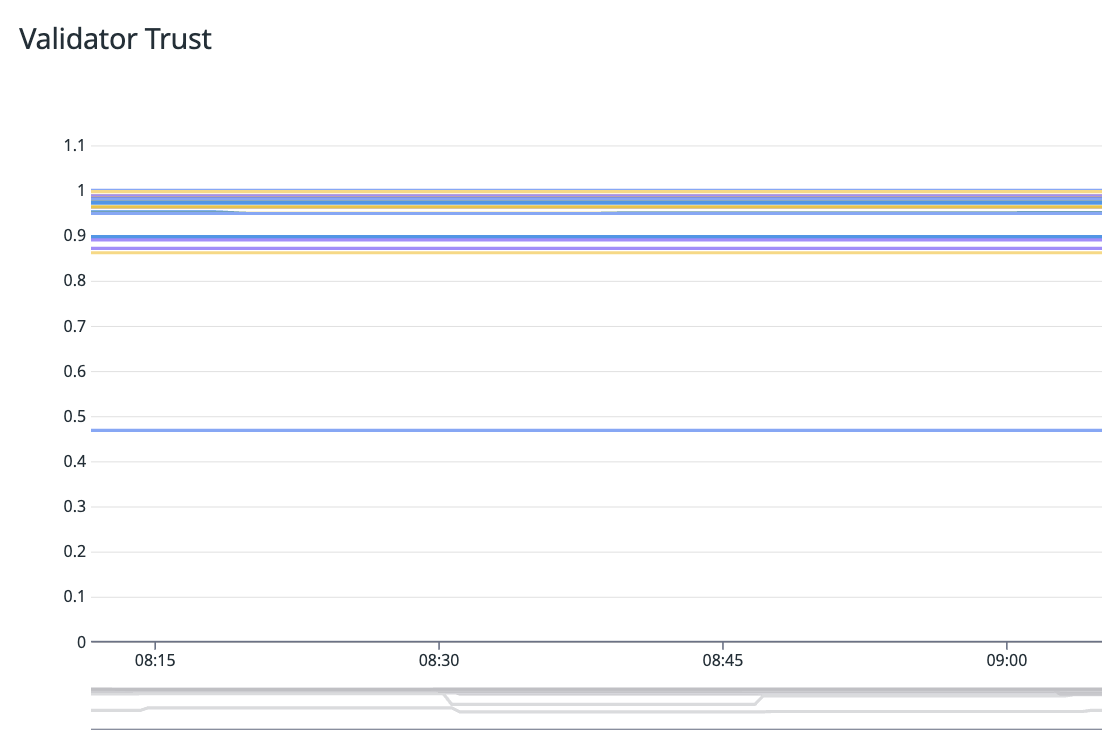
When low vTrust on a network is detected, depending on the threshold and severity the team is informed with an alert and any context that is available:

- vTrust Discrepancies: We keep a close eye on
vTrustdiscrepancies.vTrustscores are gathered from theNeuronInfostruct assembled in our bittensor monitoring post. Any deviations from the norm are flagged for immediate investigation.
After vTrust, we monitor weights across all subnets:
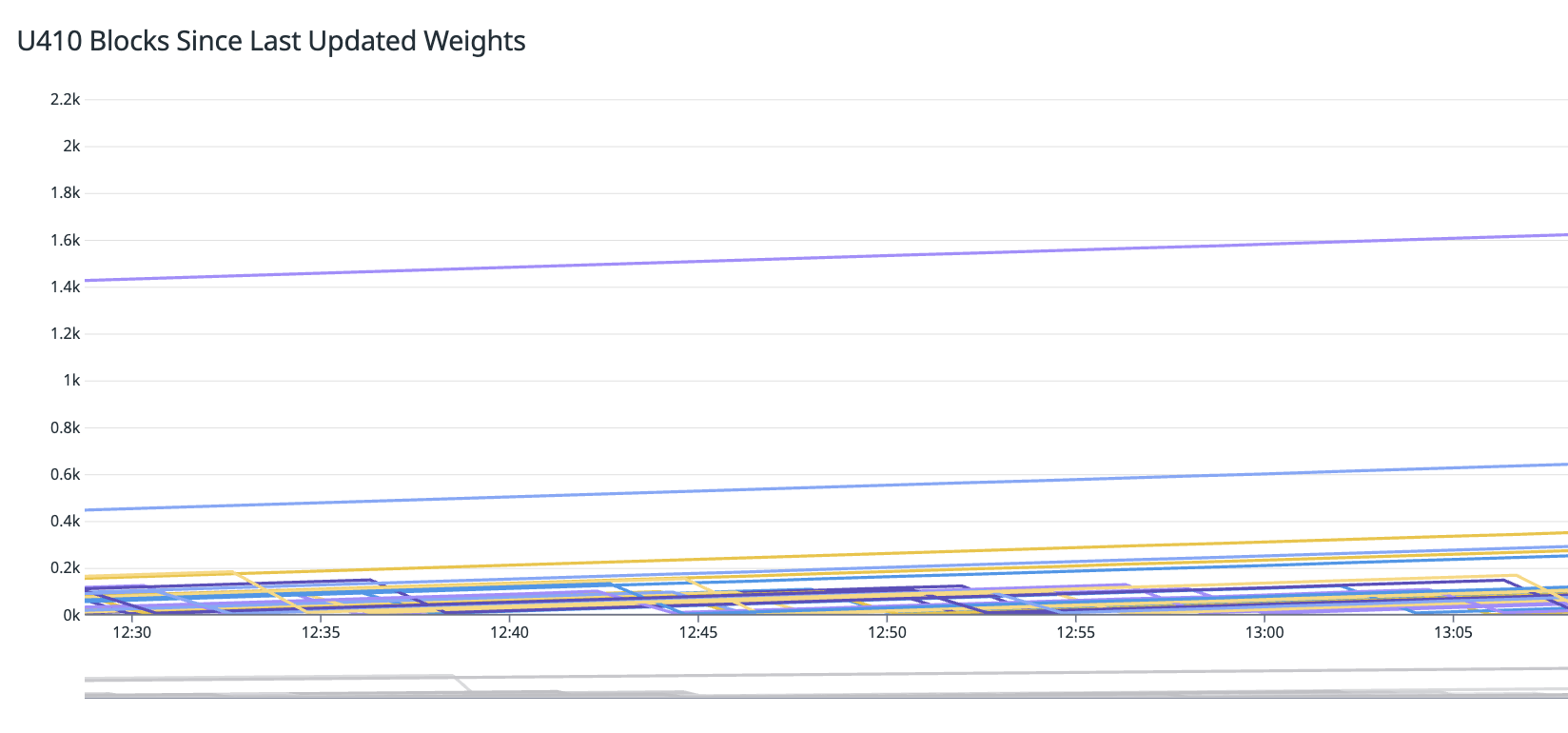
When a weight has not been set since a certain threshold, an alert is triggered:

- Blocks Since Last Set Weight: Our dashboards track the number of blocks since a validators’ last set weight. This metric is crucial for identifying stalls or performance degradation. If a validator goes too long without setting a weight, our service restarter is triggered to bring it back online quickly.
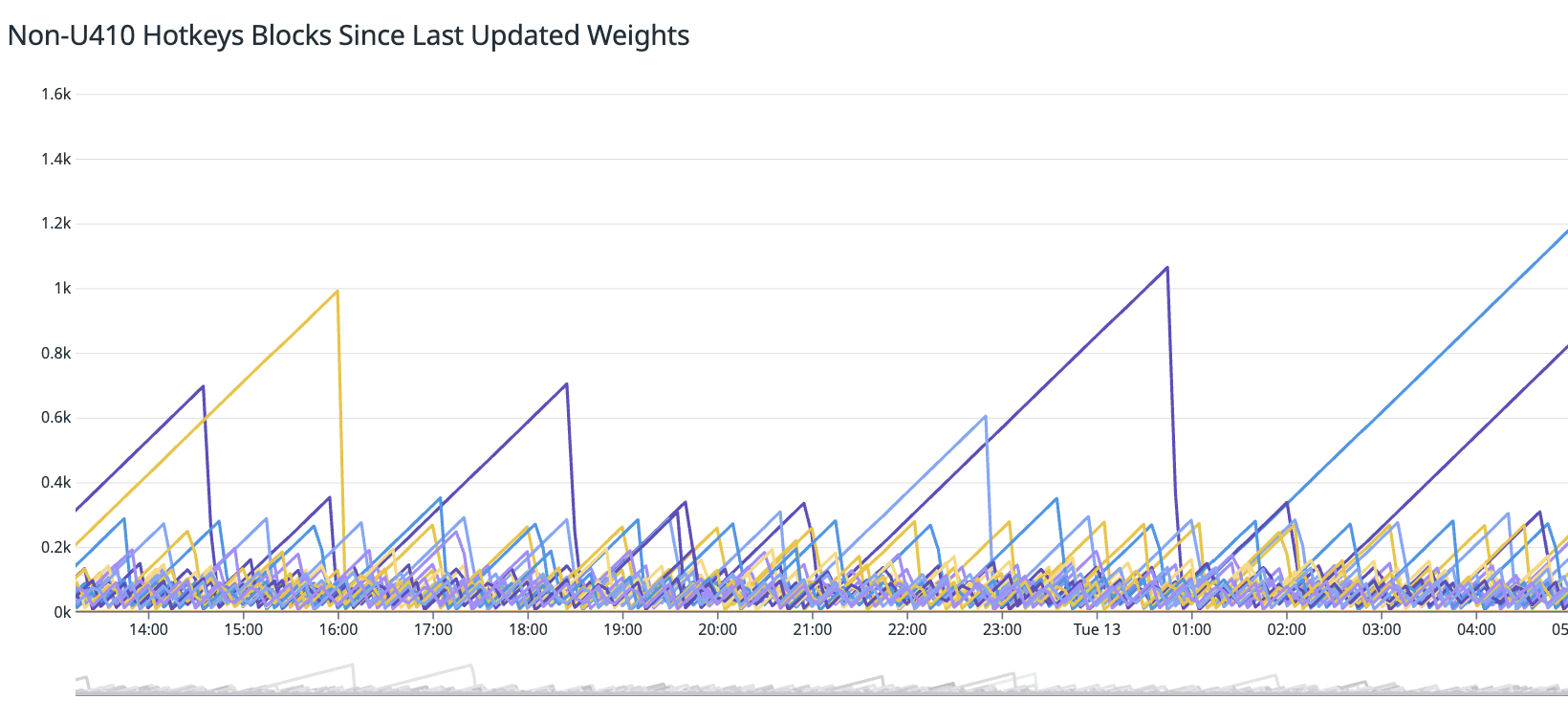
-
Performance vs. Other Hotkeys: We continuously compare hotkey performance against others in the network to obverse differences.
-
System Metrics: We monitor a range of system metrics, including CPU usage, memory consumption, network latency, and disk I/O.
Conclusion
At Unit 410, we take a meticulous approach to Bittensor validation. By combining performant hardware, secure practices, and innovative tooling, we have engineered solutions to deliver stability and high uptime.
I hope this post provides some useful insights for prioritizing security, performance, and reliability in Bittensor validation.
If topics like this are interesting to you, check out our open roles here.